 上一篇
上一篇 下一篇
下一篇
数据挖掘到底有什么不得了的?
作者:asky 日期:2006-02-16

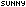

如果未来搜索引擎能进化到:
那会是怎么样的一种智能的搜索引擎呢?
其实从简单的应用中已经可以找到这种数据挖掘的影子:
我们在很多网站上都见到过一种叫作“随机码”的东东,一般是由服务器产生的一个图片,图片中是几个数字或者字母,目的就是通过无规律的标识,干扰跟踪程序的自动识别功能,因为对于人脑和电脑来说,识别一幅图中的特定信息,电脑远远不如人脑。
但是,也就有人专门针对此“随机码”进行研究,通过图形学中的降噪和特征识别,同时需要用到统计学中的很多原理,能够实现对大部分同一程序产生的随机码的识别。
最基本的数据挖掘,可以说就是“过滤”,通过人工预设的条件,对大量数据进行筛选。
从商业智能角度来看,数据挖掘的作用非同小可,如何从成千万级的数据中找到有用的数据?
- 上传一张照片
- 搜索引擎自动分析照片的特征
- 搜索引擎告诉你关于这张照片的相关信息
那会是怎么样的一种智能的搜索引擎呢?
其实从简单的应用中已经可以找到这种数据挖掘的影子:
我们在很多网站上都见到过一种叫作“随机码”的东东,一般是由服务器产生的一个图片,图片中是几个数字或者字母,目的就是通过无规律的标识,干扰跟踪程序的自动识别功能,因为对于人脑和电脑来说,识别一幅图中的特定信息,电脑远远不如人脑。
但是,也就有人专门针对此“随机码”进行研究,通过图形学中的降噪和特征识别,同时需要用到统计学中的很多原理,能够实现对大部分同一程序产生的随机码的识别。
最基本的数据挖掘,可以说就是“过滤”,通过人工预设的条件,对大量数据进行筛选。
从商业智能角度来看,数据挖掘的作用非同小可,如何从成千万级的数据中找到有用的数据?
 文章来自:
文章来自:  Tags:
Tags: 评论: 0 | 引用: 11 | 查看次数: 4988
发表评论
你没有权限发表评论!




